
课程视频
课程目标
15-799 课程主要介绍数据库查询优化器的现代实践,以及查询优化器相关的系统编程。通过课程的学习,可以掌握如下 3 部分内容:
- 查询优化器实现;
- 编写正确且高效的代码;
- 适当的文档 + 测试;
当前数据库的需求非常大,每个公司都会遇到数据库相关的问题,而查询优化器是区分不同数据库能力的关键点,因此学习查询优化器非常有价值,能够帮助大家更好地理解数据库并解决问题。
本课程包含了如下 2 个实战项目,项目 1 需要独立完成,项目 2 则需要团队合作:
- Project #1 - Query Optimizer Evaluation:动手体验流行的查询优化器,项目中你将使用 Apache Calcite 来优化 SQL 查询,然后在 Calcite(通过枚举适配器)和 DuckDB 上执行 SQL 查询;
- Project #2 - Final Project:根据示例项目,选择一个能够团队参与的项目,自行设计和完成项目。
诞生的背景
SQL 是一种声明性的查询语句,用户通常只需要通过 SQL 语句(如下展示),告诉数据库管理系统(DBMS)查询哪些数据,而不需要告诉它如何完成这些任务。
1 | SELECT DISTINCT ename |
对于一个给定的查询,DBMS 会尝试找到一个正确并且高效的执行计划,这也是本门课程的目标,即:正确(correct)、高效(best cost)地执行 SQL。
正确执行 SQL 是一个基本前提,满足了这个基本前提后,我们会更加关注 SQL 执行的效率。因此,我们需要通过代价(cost)这样的指标,来表示 SQL 执行计划的效率,从而可以对不同执行计划进行比较。
那么,查询优化和现实世界有什么样的联系呢?假设我们有 2 张表,分别是员工表(Emp)和部门表(Dept),我们使用如下的 SQL 语句,尝试从 Toy 部门查找到该部门下所有员工的不同名字。
1 | SELECT DISTINCT ename |
为了能够有效地执行这条 SQL,我们会在 Catalog 中记录列索引,包括:聚簇索引(Clustered Index)和非聚簇索引(Unclustered Index),以及表的记录数和页数。除了这些信息,Catalog 中还会记录额外的元数据,或者表中内容的摘要,这些信息会用来确定基数估计(Cardinality Estimation)、谓词选择性(Predicate Selectivity)。

按照 SQL 字面意思,我们将 SQL 语句翻译为上图所示的执行计划,最底部我们对 Emp 和 Dept 进行扫描,然后对他们进行笛卡尔积运算。从图中可以看到,笛卡尔积运算需要进行大量的读写 IO 操作,并且后续的选择操作(包括:Emp.did = Dept.did 连接条件、dname = 'Toy' 过滤条件 )需要重新读回全部写入数据。过滤操作完成后,我们会对最终的查询结果进行投影,得到我们需要的员工名字。
因此,如果我们直接将 SQL 按照字面意思翻译为执行计划,那么整个执行过程大约需要 200 万次 IO 操作,这个查询成本显然是非常高的。那么,我们可以让这条 SQL 执行地更高效吗?为了实现这个目标,首先可以假设 I/Os 是成本指标中的一项,我们可以根据 I/Os 大小,来简单确定某个执行计划是否是最优的,降低 I/Os 可以直接提升 SQL 执行效率。
前文生成的执行计划采用的是笛卡尔积 Join,这会产生大量的 I/Os 操作,为了减少 I/Os 成本,可以将关联条件 E.did = D.did 下推到 Join 中,这样就可以使用其他更高效的 Join 运算符,例如:Page Nested-Loop Join,下图展示了 Page Nested-Loop Join 的执行计划,由于提前过滤 Join 关联条件,整个执行计划只需要 5 万 4 千次 I/Os。

优化器的职责就是识别出哪些执行计划效率低,并将这些低效率的执行计划优化为语义等价且高效的执行计划。优化器可能会进行更进一步地优化,例如:使用 Sort Merge Join 来替换 Page Nested-Loop Join,这种操作本质上改变了 Join 运算符的物理运算符。
除了 Join 运算符层面的优化,优化器还可以对查询执行模型进行优化,例如我们使用物化模型(Materialization Model)进行查询,每个运算符都需要执行完所有操作,并将数据写入到临时文件中,然后再从临时文件中读取出来,这种执行模型没有采用流水线执行方式(No Pipelining)。我们可以尝试将执行模型切换为向量化执行模型(Vectorization Model),它可以充分利用流水线的优势,无需完成运算符的所有数据计算,只需要向上传递一个元组向量,整体的 I/Os 可以下降一半。

前面我们讨论的主要是如何对 Join 运算符进行优化,除了 Join 优化外,还可以将谓词下推到 Join 运算符之下,从而大幅度减少 I/Os。dname = 'Toy' 是 Dept 表的谓词,如果在 Join 之后做谓词过滤,则会导致 Join 的计算量特别大,因此优化器会将谓词下推到 Join 运算符之下,这样优化后的 I/Os 可以降低到 37。

经过这些优化,我们可以看出优化器的重要价值,从最开始的 200 万次 I/Os,一直减少到 37 次 I/Os,SQL 执行的性能也因此大幅度提升。以上展示的还只是一个简单的 SQL Case,对于复杂的 CTE,嵌套子查询,优化器带来的性能提升将会更高。
优化器介绍
DBMS 概览
下图展示了 DBMS 的整体架构,应用程序通过 SQL 访问 DBMS,首先通过 SQL 解析器(Parser)对 SQL 字符串进行处理,不同的数据库会有不同的 SQL 方言,SQL 解析器将会识别出这些方言,然后生成抽象语法树(Abstract Syntax Tree)来表示 SQL。
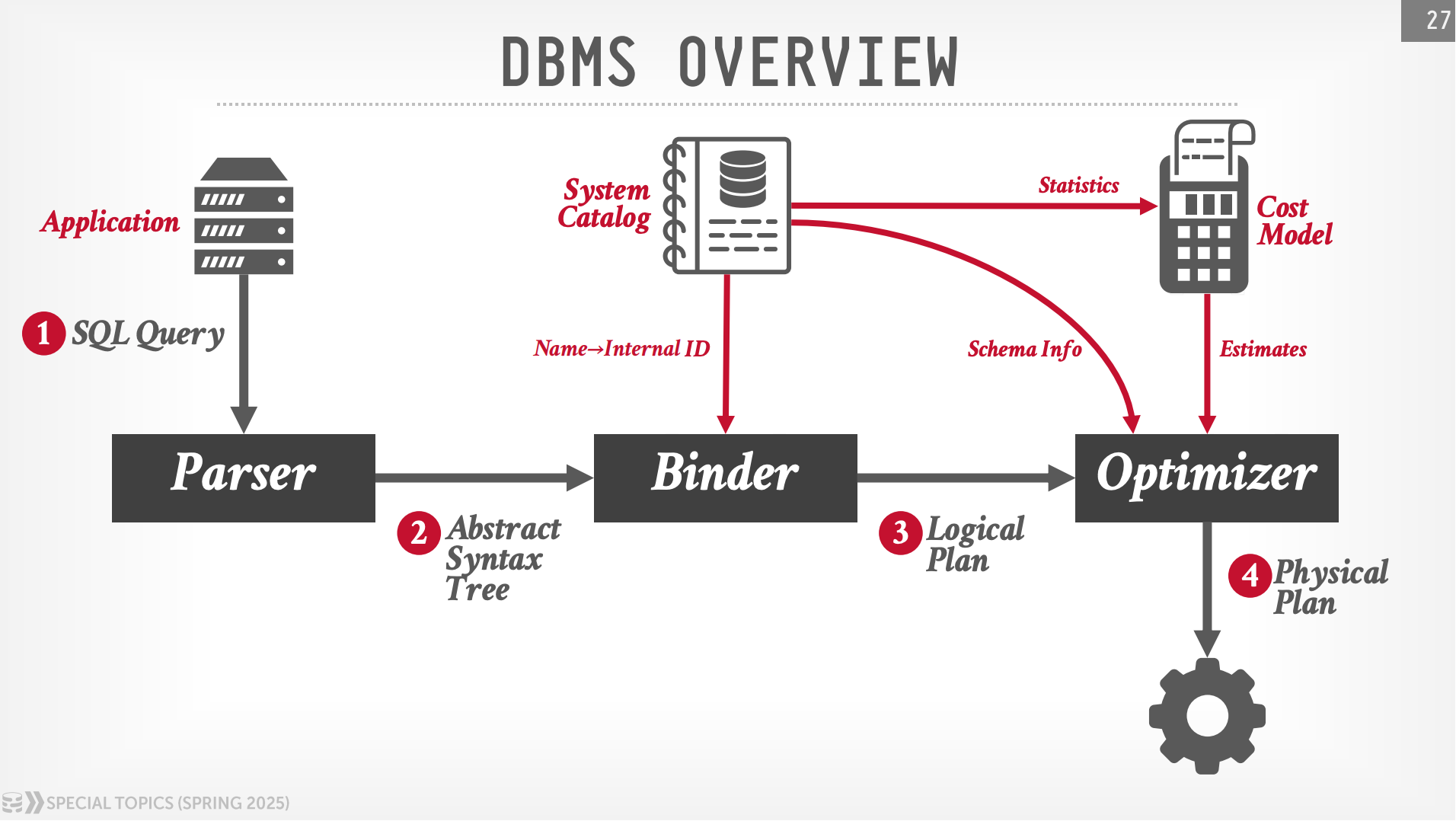
下一个阶段,会将抽象语法树输入到绑定器(Binder)中,绑定器也叫分析器(Resolver),它负责查看抽象语法树中的标记(Token),并将这些标记转换为数据库对象,例如:对于给定的表名,它的内部标识符或对象 ID 是什么?如果 SQL 引用了不存在的表,绑定器可能会抛出异常。为了完成 SQL 绑定,每个数据库都会维护系统目录(System Catalog),它是关于数据库的数据库,内部存储了表的元数据信息,例如:表包含哪些列,列的类型,是否有物化视图、虚拟视图或触发器等。
绑定器会生成初始的逻辑执行计划,这个执行计划像是对抽象语法树的精确翻译,并且采用了关系代数进行表示,逻辑执行计划没有具体说明要如何执行。优化器(Optimizer)接收到逻辑执行计划后,内部会基于代价模型(Cost Model)计算代价,计算代价的过程中,需要从系统目录中获取统计信息(包括:行数、列值的分布特征),然后采用一些计算公式,估算出某个运算符的执行代价,然后选择代价最小的执行计划。最终,优化器会生成代价最小的物理执行计划,物理执行计划中声明了要如何执行,执行器(Executor)根据物理执行计划就可以完成 SQL 执行。
查询优化器
查询优化器负责根据输入的逻辑执行计划,生成对应的物理执行计划。查询优化器的目标主要包含以下几点:
- 从一个巨大的搜索空间中,寻找出高效的执行计划;
- 准确区分出一个执行计划,是否比另外一个执行计划更好;
- 高效地查找搜索空间,找出代价最低的物理执行计划;
理想情况下,不管查询表达式如何书写,查询优化器都要能够生成出最佳的执行计划(复杂的 SQL 场景下,找出最优执行计划的过程就需要消耗大量时间,因此通常会找出相对高效的执行计划)。
逻辑计划 VS 物理计划
物理执行计划由物理运算符组成,物理运算符则定义了具体的执行策略,例如:访问路径、Join 算法等。物理运算符还会依赖他们处理数据的物理格式,例如:排序、压缩等。需要注意的是,逻辑运算符和物理运算符并不是 1:1 对应的,例如:逻辑运算符 LogicalScan 可以转换为 TableScan 或 IndexScan,逻辑运算符 LogicalJoin 可以转换为 NestedLoopJoin、SortMergeJoin 或 HashJoin。
课程主题
如下是 15-799 查询优化课程包含的主题:
- 搜索策略(
Search Strategies) - 枚举 / 转换(
Enumeration / Transformations) - 并行化(
Parallelization) - 统计 / 汇总(
Statistics / Summarization) - 基数估计 / 参数化(
Cardinality Estimation / Parameterization) - 自适应 / 反馈机制(
Adaptivity / Feedback Mechanisms) - 现实世界的实现(
Real-world Implementations)
搜索策略
启发式规则:
- 重写查询以消除(猜测的,或基于经验的)低效率的运算符;
- 例如:始终先进行选择,或尽可能早地下推投影;
- 这些技术可能需要检查目录(
Catalog),但不需要检查数据。
基于代价的搜索:
- 使用模型估算执行计划的成本;
- 列举查询的多个等效计划,并选择成本最低的计划。
自上而下 VS 自下而上

自上而下优化:
- 从查询所需的结果开始,然后沿着树向下查找能够实现该目标的最佳计划;
- 例如:
Volcano、Cascades。
自下而上优化:
- 从零开始,然后制定计划,以实现你想要的结果。自下而上优化是边进行,边构建所需的运算符;
- 例如:
System R、Starburst。
优化对象
数据库优化器在优化一条查询时,优化的目标很多,主要如下:
- 降低 SQL 响应时长;
- 降低资源消耗;
- 降低硬件成本;
- 提升吞吐量;
数据库管理系统使用代价模型(Cost Model)来预测执行计划在数据库中的表现,注意:代价(Cost)是数据库内部的值,用来比较不同执行计划的优劣,我们不能拿 Cost 值去和其他系统的 Cost 值去进行对比,也不能拿 Cost 值和 SQL 中的数值进行对比,它们可能完全不同。一些数据库管理系统,会记录最优执行计划,和次优执行计划,然后内部执行进行对比验证,用来检查执行计划是否准确可靠。
优化粒度
优化粒度是指查询优化器做优化时,以多大的范围作为优化单元。
- 单查询优化(主流传统数据库 MySQL、PostgreSQL、Oracle,这些都默认采用了单查询优化,每条 SQL 单独解析、单独生成执行计划,互相隔离,互不感知):
- 搜索空间小得多;
- 数据库管理系统通常无法跨查询复用计算结果;
- 若要考量资源争抢,代价模型必须感知当前正在执行的任务;
- 多查询联合优化(多查询联合优化,会一次性接收一批查询,全局统筹规划执行,提取公共表扫描、公共子表达式、中间结果缓存复用,目前还仅限于研究,没有大规模使用):
- 存在大量相似查询时,优化效率更高;
- 整体搜索空间会大幅膨胀;
- 支持数据、中间计算结果复用共享;
结语
查询优化实现难度极高,是数据库管理系统中最难完善实现的模块(该问题已被证明属于 NP 完全问题)。同一条查询会存在多种备选执行计划,各计划的运行时性能表现差异极大。
NP-Complete:NP 完全问题,属于计算复杂性理论,不存在多项式时间的最优求解算法。
没有任何一款优化器能真正生成理论上的最优执行计划。依靠统计估算手段预测各执行计划的实际开销。
- 对应技术:基数估算、统计信息采样、选择性预估等,估算值和真实数据存在偏差。
采用启发式规则缩小计划搜索空间。
- 对应技术:连接顺序剪枝、谓词下推、限制连接表数量等,牺牲全局最优换取优化速度。
参考资料
EQOP Book (Chapter 1)
An Overview of Query Optimization in Relational Systems (S. Chaudhuri, PODS 1998) (Optional)