
前言
前文 Calcite:跳出 SQL 查询优化,转向数据优化主要讨论了一个问题:分析系统的性能上限,很多时候取决于数据被怎样组织。索引、排序、分区、缓存、物化视图、列式格式、空间填充曲线,其实都在做同一件事:把数据预先整理成查询更容易消费的形态。
顺着这个问题继续探究,真正棘手的是如何工程化落地。预先处理的数据如何被系统使用?查询进来,优化器如何知道可以走索引、汇总表或缓存结果?工作负载变化后,哪些数据副本该保留,哪些该刷新,哪些该淘汰?
Julian Hyde 在 Tactical Data Engineering 这场分享里,讨论了这些具体的工程实践问题。他把数据工程里经常出现的方法归成几类:caching、partitioning、sorting、derived data sets。这些能力在 DBMS 里已经成熟,后来又逐步应用到现代数据流水线、BI 语义层和云数仓等领域。为了方便不同领域的工程化落地,可以借助 Calcite 项目来完成这些工作,Calcite 内部统一使用关系代数和查询优化框架,让这些数据组织方法能够快速集成,并进行系统级优化。
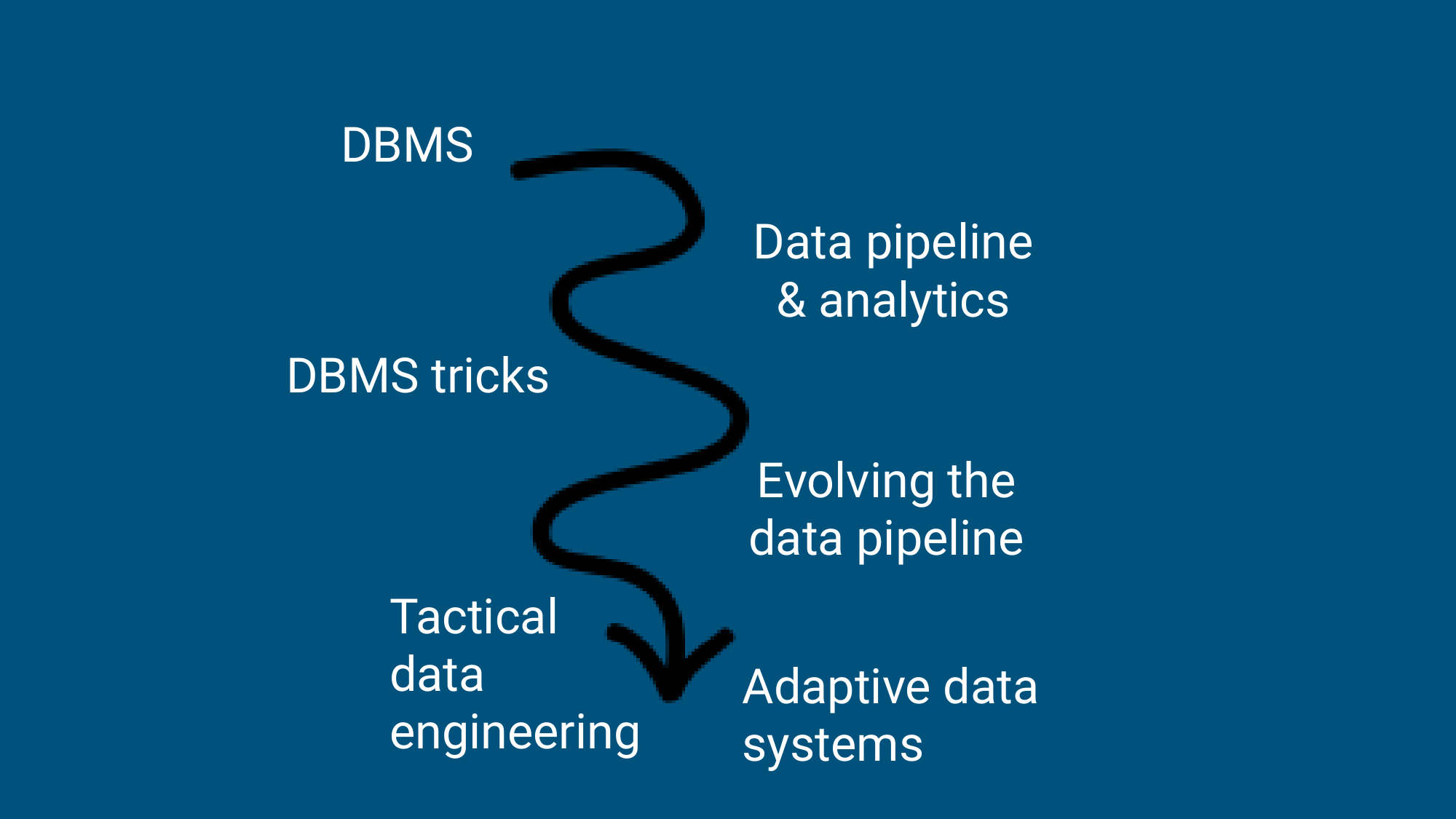
上图展示了战术数据工程的演进路径,本文会顺着分享的思路,逐个主题为大家介绍。首先了解 DBMS 为什么能靠重组数据提升查询,再看看现代数据流水线,为什么又把这些能力拆散。然后我们再来了解 Calcite 的关系代数和物化视图重写,最后再学习 Looker 派生表、Lattice 汇总表选择和自适应数据系统。
flowchart LR
A[DBMS 经验] --> B[现代数据流水线]
B --> C[数据重组模式]
C --> D[Calcite 关系代数与优化]
D --> E[Looker 派生表]
E --> F[Lattice 与物化视图选择]
F --> G[自适应数据系统]DBMS 的价值:重组数据,再改写程序
分享开头用文件系统和 DBMS 做对比:如果程序直接读两个文件进行 Join,程序员需要自己处理扫描、匹配、排序和中间状态。DBMS 通过引入表、查询语言和优化器,使得用户可以直接写声明式查询,DBMS 系统根据 SQL 语义,负责生成执行计划,然后决定访问路径。
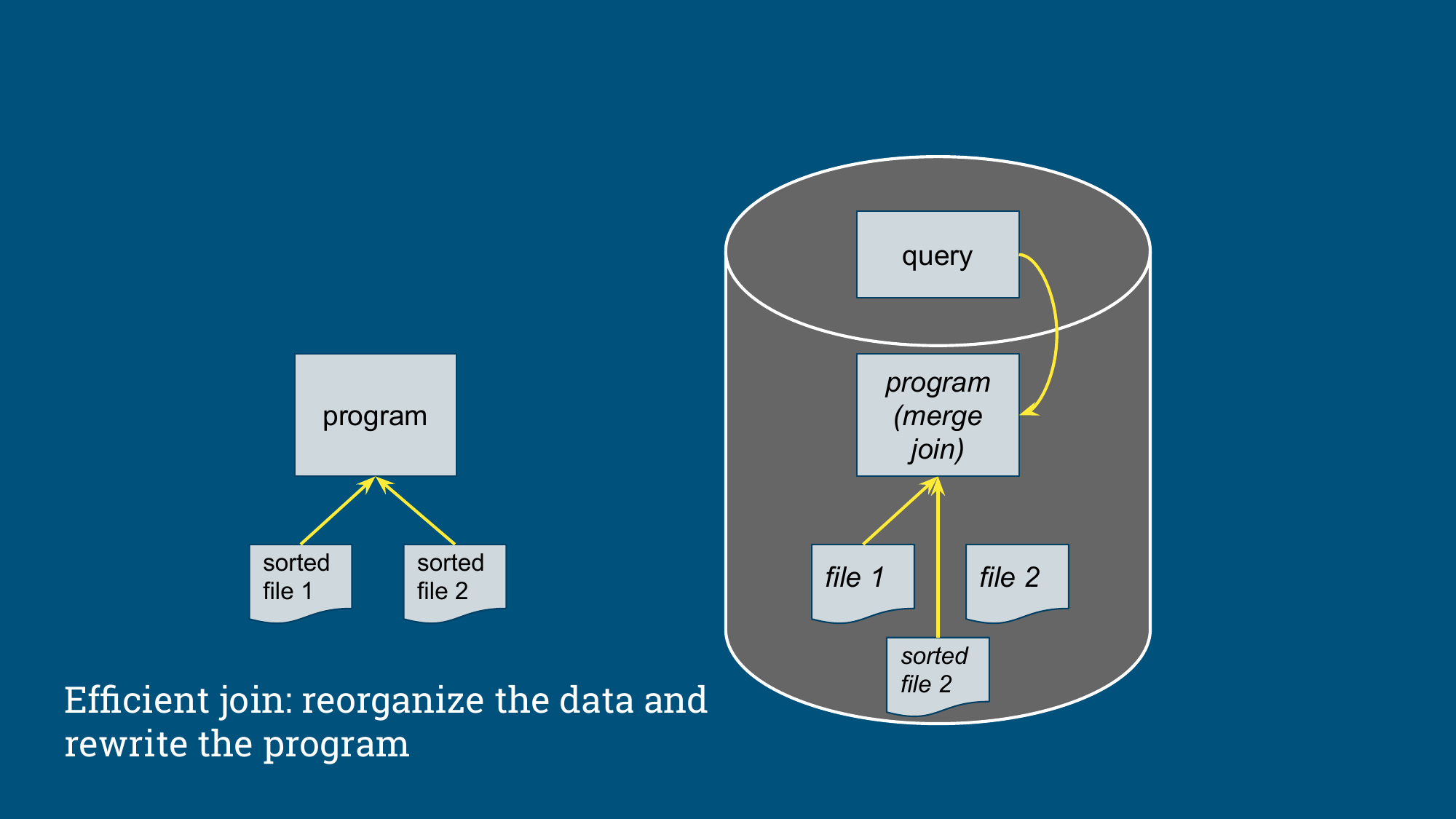
高效 Join 往往来自数据重组和执行程序改写,例如先排序再执行 merge join,表面看这是查询优化,深入探究其实内部包含了两个步骤:
- 重组数据。例如将两个输入按
Join key排序; - 改写程序。例如把原来的嵌套循环或全量匹配,换成
merge join。
放到这个例子里,前文组织数据优先于优化查询的观点就更具体了:优化器依赖可替换的数据形态、可重写的执行计划,以及足够多的访问路径。当系统具备排序、索引、分区、汇总表这些数据副本,优化器才有空间把查询换成更便宜的路径。
Julian Hyde 在列举 DBMS 的价值时,提到了抽象、声明式语言、查询优化、数据重组、新算法、治理、元数据和安全,这些都是大家熟知的 DBMS 的价值。最后他还补了一项 adaptability,也就是系统需要根据查询、DML 和统计信息持续调整数据组织方式。这件事很难长期靠 DBA 手工维护,也是 tactical data engineering 想解决的问题。
数据流水线为什么会重新发明 DBMS
现代分析流水线常见形态是 Extract - Load - Transform。数据先从多个源进入云数据库,分析师和业务用户再通过 SQL 或 BI 工具发起交互式查询。表面上看,这是数据工程问题;从系统结构看,它很像一个被拆开的 DBMS。
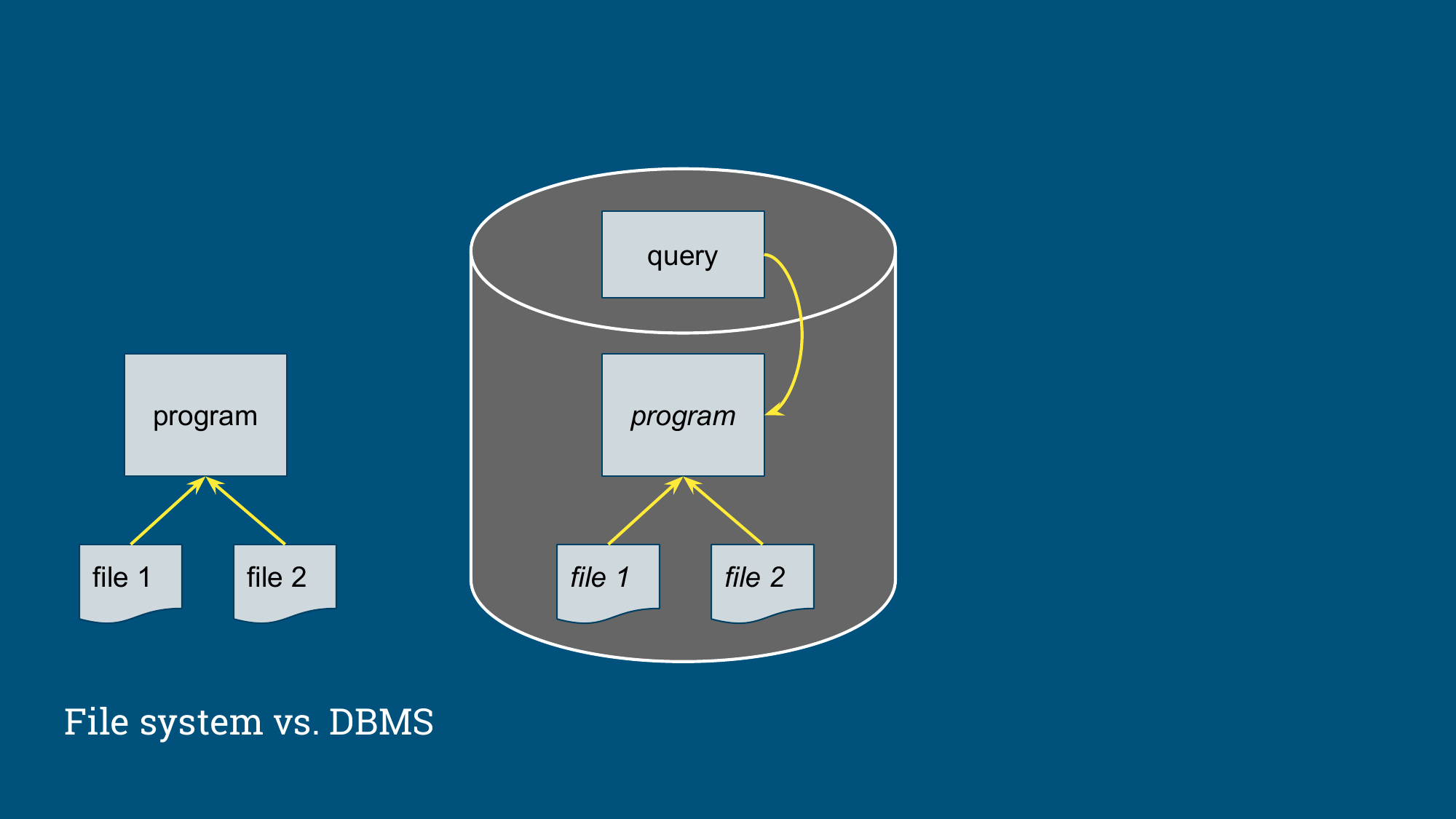
图:分析型数据系统把文件、程序、Cloud DB、SQL 查询和业务查询放到同一个链路里
DBMS 把“数据如何存、查询如何跑”封装在一个系统里。现代数据栈把这些职责拆给了对象存储、云数仓、ETL 工具、BI 工具、调度器和缓存层。灵活性变高之后,责任也跟着散开:谁负责决定什么时候建汇总表?谁负责缓存?谁负责淘汰过期派生数据?谁负责保证派生表和业务模型一致?
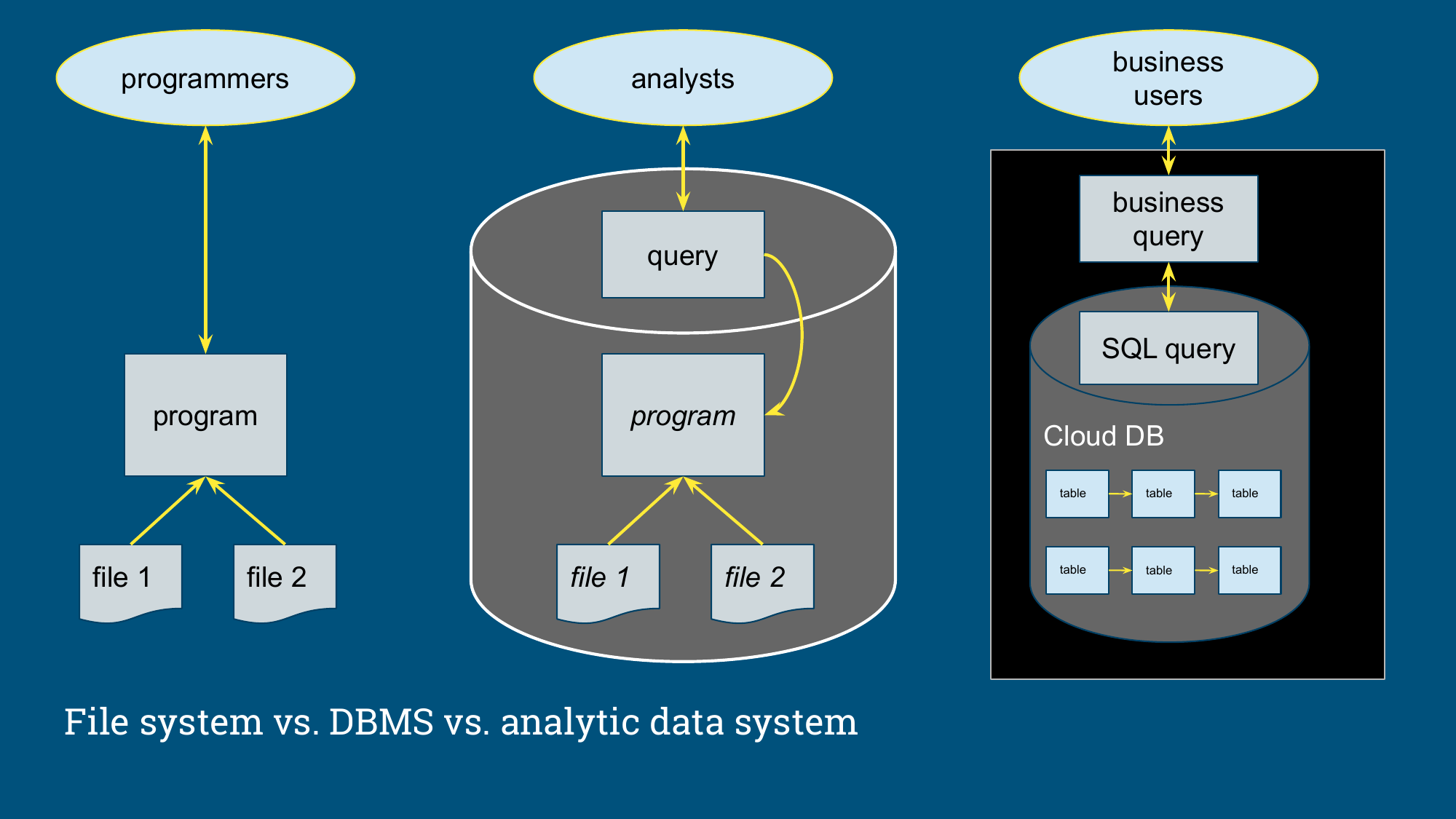
图:数据工程会随工作负载演进,数据工程师、分析师、数据科学家和系统本身都参与数据组织
这里的“战术”,更接近一层渐进控制:在现有系统之上补一层可演进的能力,让数据组织跟着真实工作负载调整。
- 数据工程师负责定义关键模型和生产化路径。
- 分析师通过语义层和 BI 工具提出新的访问模式。
- 数据科学家带来探索性查询和临时特征加工。
- 系统根据运行时反馈做缓存、分区、物化和淘汰。
这些角色都会改变数据布局。最后这些变化还要落到系统能处理的表达上:代数、规则、代价和可执行计划。Calcite 这样的框架负责承接这一层。
Calcite:战术数据工程的优化层
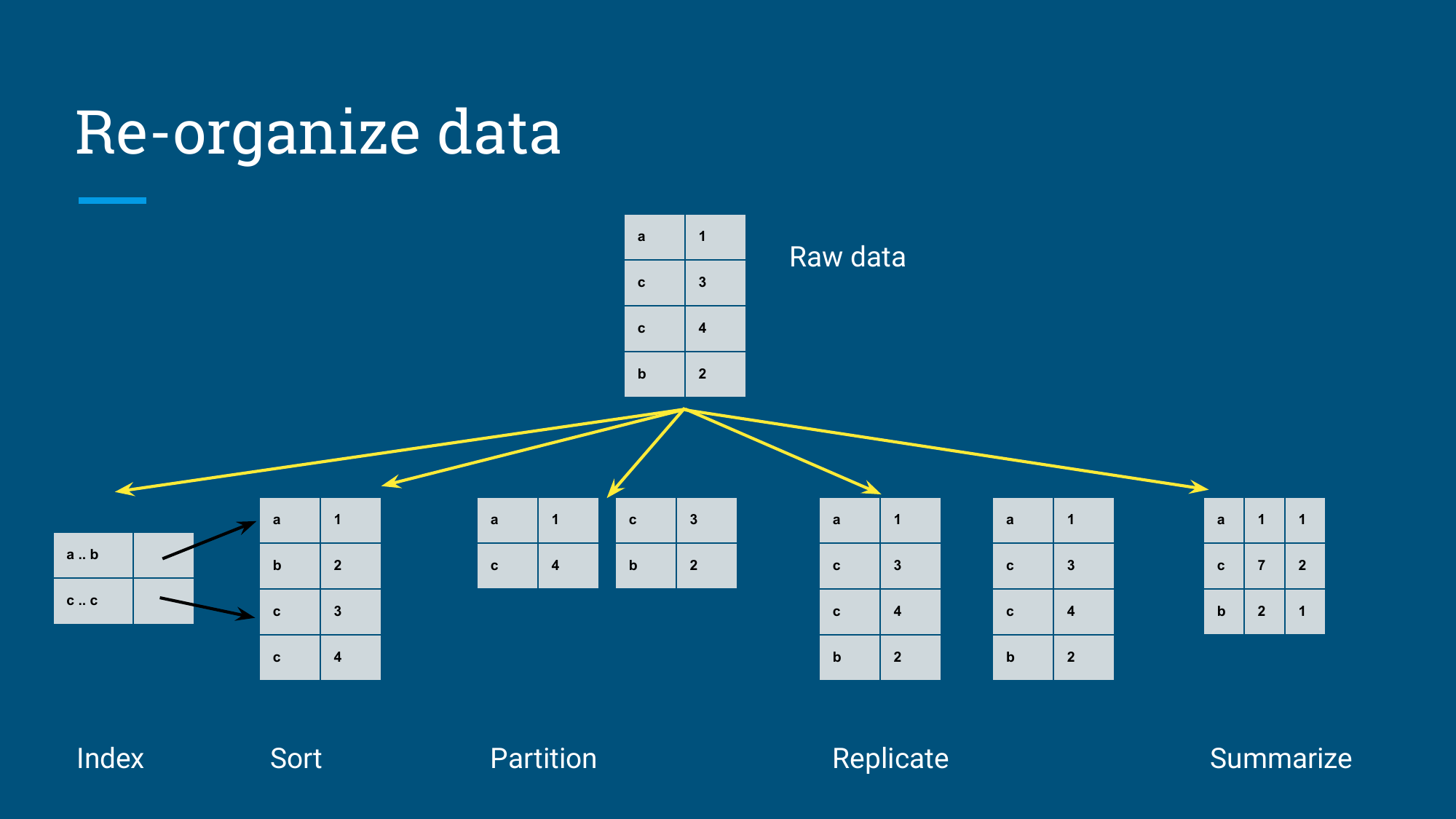
图:Calcite 是 Apache 顶级项目,提供查询优化框架,也可以作为带 SQL/JDBC 前端的联邦查询引擎独立运行
Calcite 没有自己的存储引擎,也不绑定某个执行引擎。它提供的是查询处理的中间层:
- SQL 解析与校验。
- 关系代数树
RelNode。 - 规则重写与代价优化。
- 方言转换和适配器扩展。
- 物化视图、Lattice、联邦查询等优化能力。
Calcite 把执行和存储留给外部系统,现代数据栈里的很多系统都可以接进来。云数仓、搜索引擎、KV 存储、流引擎、BI 平台可以把自己的能力注册给 Calcite:哪些算子能下推,哪些索引可用,统计信息是什么,返回的数据分布如何。Calcite 在上层做全局优化,再把局部计算推回合适的数据源。

图:SQL 被转换成 Project、Filter、Aggregate、Join、Sort 等关系代数节点
分享里的 SQL 例子很典型:
1 | SELECT d.name, COUNT(*) AS c |
这条 SQL 会被转换成一棵关系代数树:Scan、Join、Filter、Aggregate、Project、Sort。重写规则直接操作这棵树,SQL 字符串只作为输入。只要规则保持语义等价,系统就可以尝试把 Filter 放到 Join 之前、把聚合提前、替换底层扫描,或者把查询转成另一个数据源能执行的方言。
Hyde 在讲义中强调了一个细节:规则生成的“新计划”不一定总是更便宜,所以优化器会保留改写前后的表达式,再用动态优化寻找总代价最低的方案。这是 Volcano/Cascades 一类优化器的基本思想,也是 Calcite 能同时处理规则优化和代价优化的基础。
视图与物化视图:从展开到替换
普通视图解决的是复用问题。用户查询 Managers 视图时,优化器先把视图展开成它背后的查询,再和外层查询合并优化。
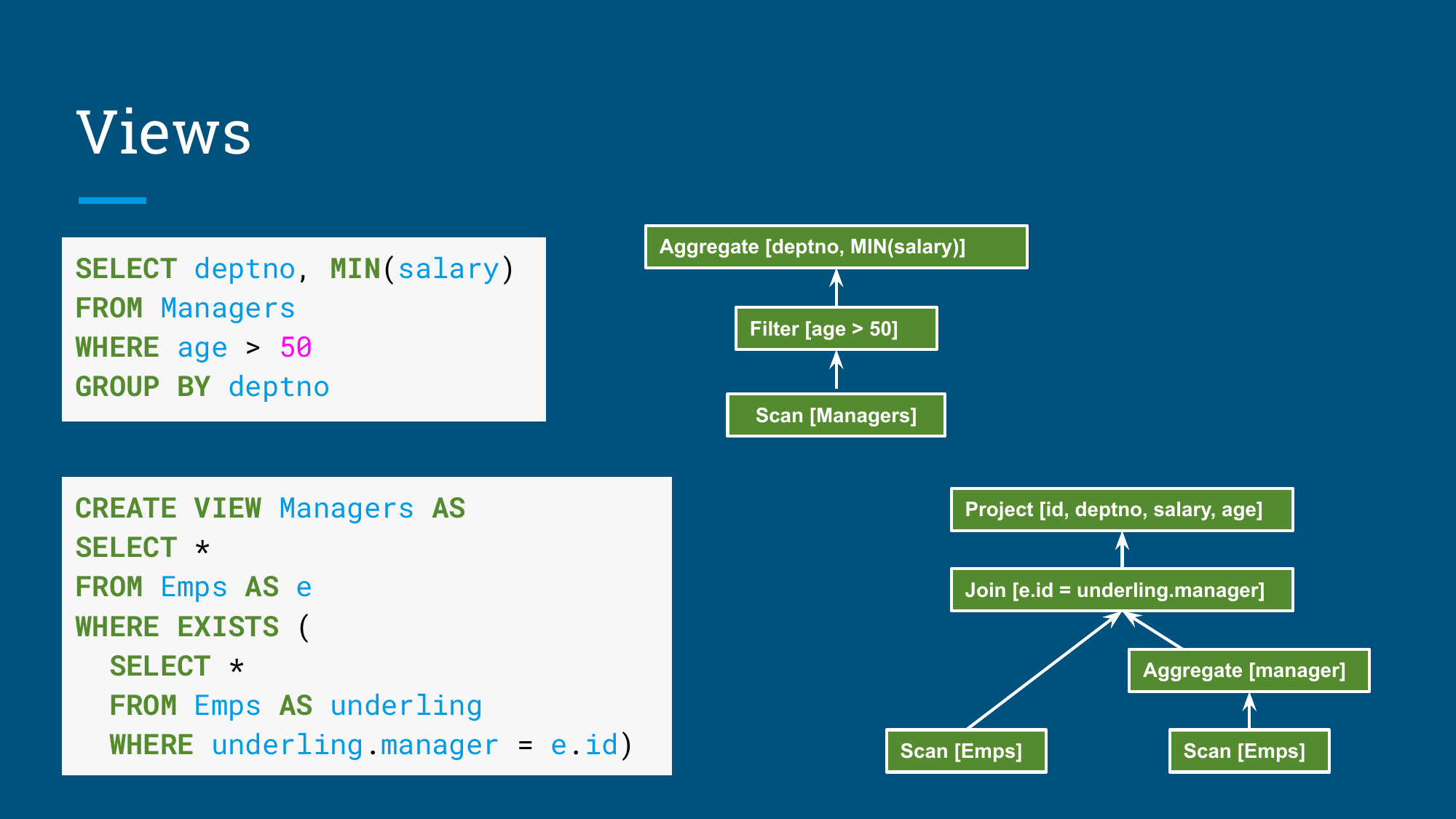
图:普通视图会先展开成底层关系表达式,再参与整体优化
物化视图多了一步:它已经把某个关系表达式的结果保存成表。优化器的任务变成识别“当前查询能不能由这个已保存结果回答”。分享里用 EmpSummary 展示了这个过程:
1 | CREATE MATERIALIZED VIEW EmpSummary AS |
用户查询:
1 | SELECT COUNT(*) AS c |
Calcite 的重写过程可以理解为四步:
- 把用户查询表示成关系代数树。
- 把物化视图也表示成等价的关系代数树。
- 判断用户查询是否可以落到物化视图的粒度上。
- 用
EmpSummary的TableScan替换原始Emps扫描,并在上层补上Filter和Project。
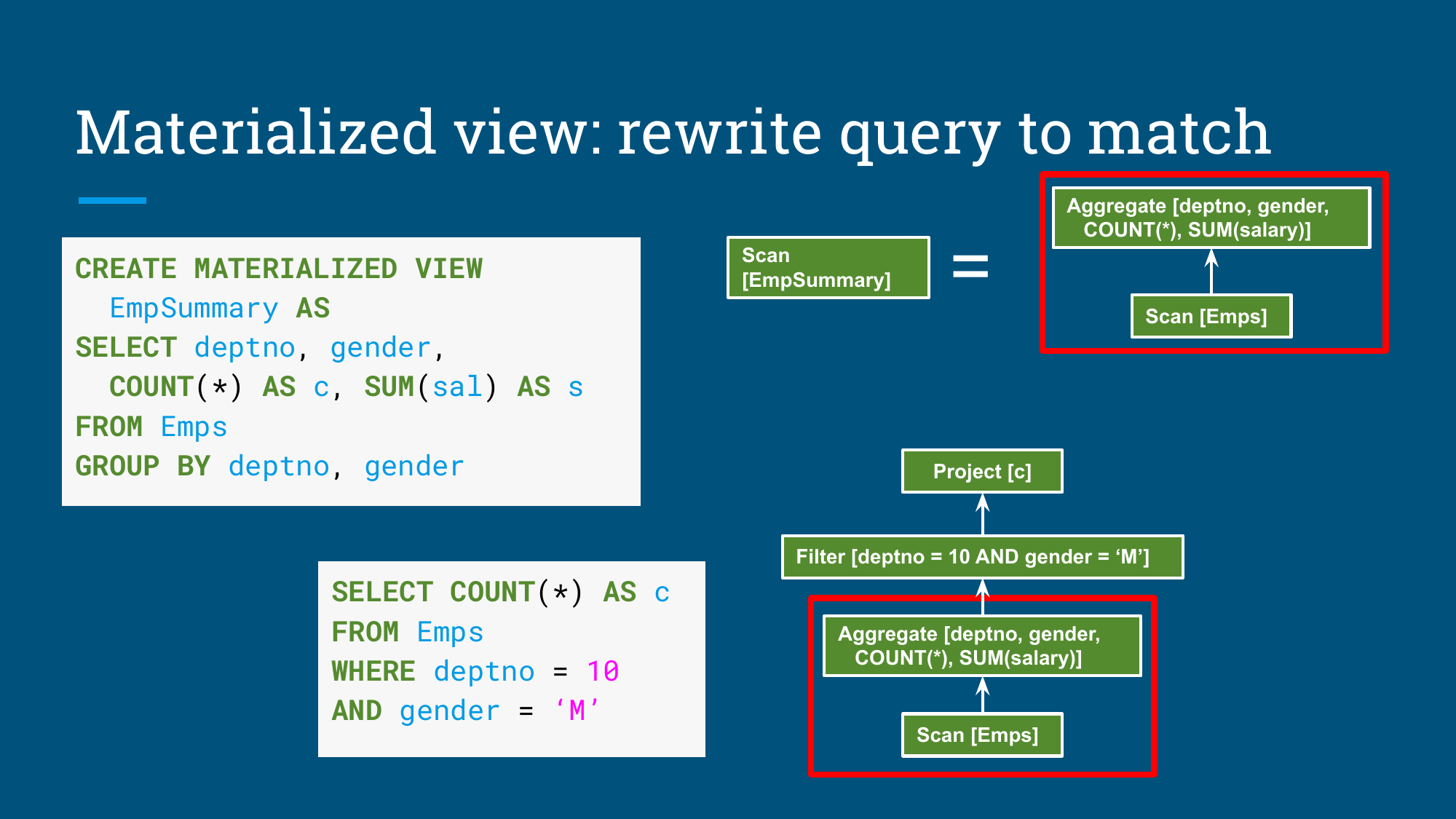
图:物化视图重写的中间态,查询被改写成可匹配 EmpSummary 的形态
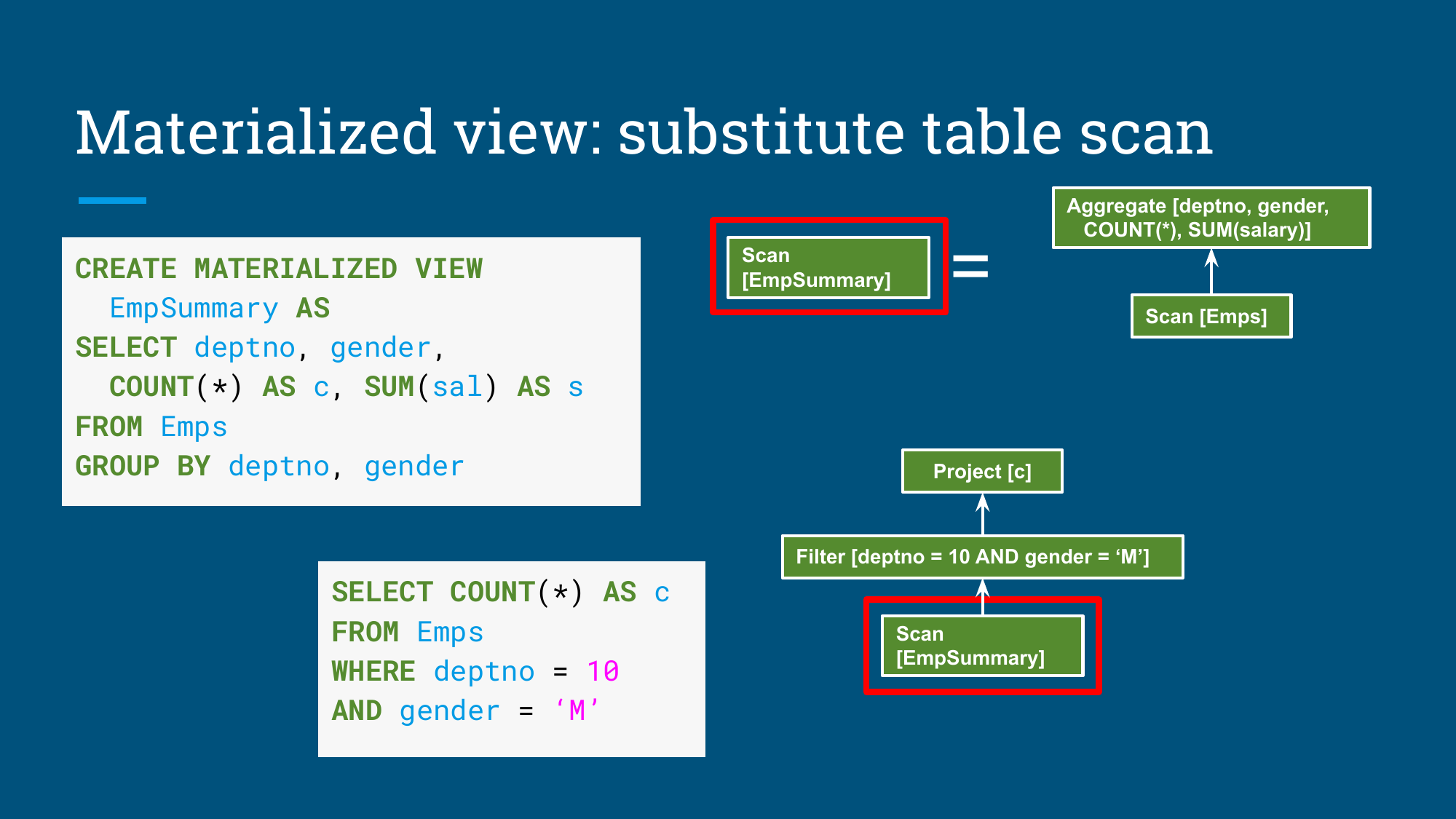
图:匹配成功后,原始表扫描被物化视图扫描替代
这里最容易漏掉的是汇总表的派生语义:它来自哪个关系表达式、保留了哪些维度、提供了哪些聚合指标、需要哪些补偿计算。优化器拿到这层代数语义后,物化视图才可能成为透明优化手段;只保存一张物理表,最后通常还是回到人工命名和人工改 SQL。
Looker 派生表:把 ETL 和缓存的边界做薄
Tactical Data Engineering 的案例部分落在 Looker。Looker 的 LookML 允许团队定义维度、度量和 Explore,业务用户在前端组合字段,底层生成 SQL。这个模型和 Calcite 的思路很接近:前端表达业务意图,底层通过关系表达式和 SQL 生成机制执行。
分享先给了一个 orders view 的例子:id、customer_id、amount 是维度,count、total_amount 是度量。之后引入更关键的 derived_table:
1 | view: customer_order_facts { |

图:LookML 可以用 SQL 或 Explore 定义派生表
这个例子把“客户首单日期”和“客户生命周期金额”从订单明细中提前聚合出来。它既像 ETL,又像缓存:
- 作为 ETL,它把常用业务事实沉淀为独立模型。
- 作为缓存,它可以按使用情况创建、过期和重建。
- 作为语义层的一部分,它能继续暴露维度和度量,供业务查询复用。
讲义把派生表分成三类:
| 派生表类型 | 用途 | SQL 近似形式 |
|---|---|---|
Ephemeral | 查询展开,每次使用时内联到 SQL 中 | CREATE VIEW |
Persistent | 查询执行一次,结果保存到表,在过期前被多次使用 | CREATE TABLE AS SELECT |
Transparent | 后台按持久派生表填充,即使业务查询没有显式引用也可以被优化器命中 | CREATE MATERIALIZED VIEW |

图:Looker 派生表的三种形态:Ephemeral、Persistent、Transparent
这三类派生表放在一起看,像是数据工程的三个阶段。先用临时展开验证模型,再把高频模型持久化,最后让优化器透明命中它。团队可以沿着真实查询负载逐步生产化,把一次性 ETL 设计拆成更小的演进步骤。
物化视图建设是一组工程问题
讲义里对物化视图建设的拆分,可以直接翻成工程任务:

图:物化视图建设包含设计、填充、维护、重写、适配和表达六项任务
| 任务 | 工程含义 |
|---|---|
Design | 选择哪些物化结果值得创建 |
Populate | 用批任务或增量任务填充数据 |
Maintain | 数据变化后维护一致性 |
Rewrite | 查询到来时透明改写到物化结果 |
Adapt | 新建高收益物化结果,淘汰低收益结果 |
Express | 用足够丰富的代数表达数据如何派生 |
最后一项经常被低估。系统要能自动使用物化视图,必须知道派生表的语义来源。只保存一张物理表不够,还要保存它对应的 Join 路径、Group By 粒度、聚合函数、过滤条件、函数依赖和统计信息。Calcite 在这里派上用场:先用关系代数表达这些派生关系,再用规则和代价模型决定是否替换。
Lattice:在星型模型里选择汇总表
物化视图难在选择。一个星型模型有几十个维度时,可选汇总表数量会迅速膨胀。全部物化不可行,手工挑选也容易滞后。Calcite 的 Lattice 用来描述星型模型里的事实表、维表、Join 路径和候选汇总表。
讲义中的示例是 Sales Lattice:
1 | CREATE LATTICE Sales AS |
用户常查的汇总可能是:
1 | CREATE MATERIALIZED VIEW SalesYearZipcode AS |
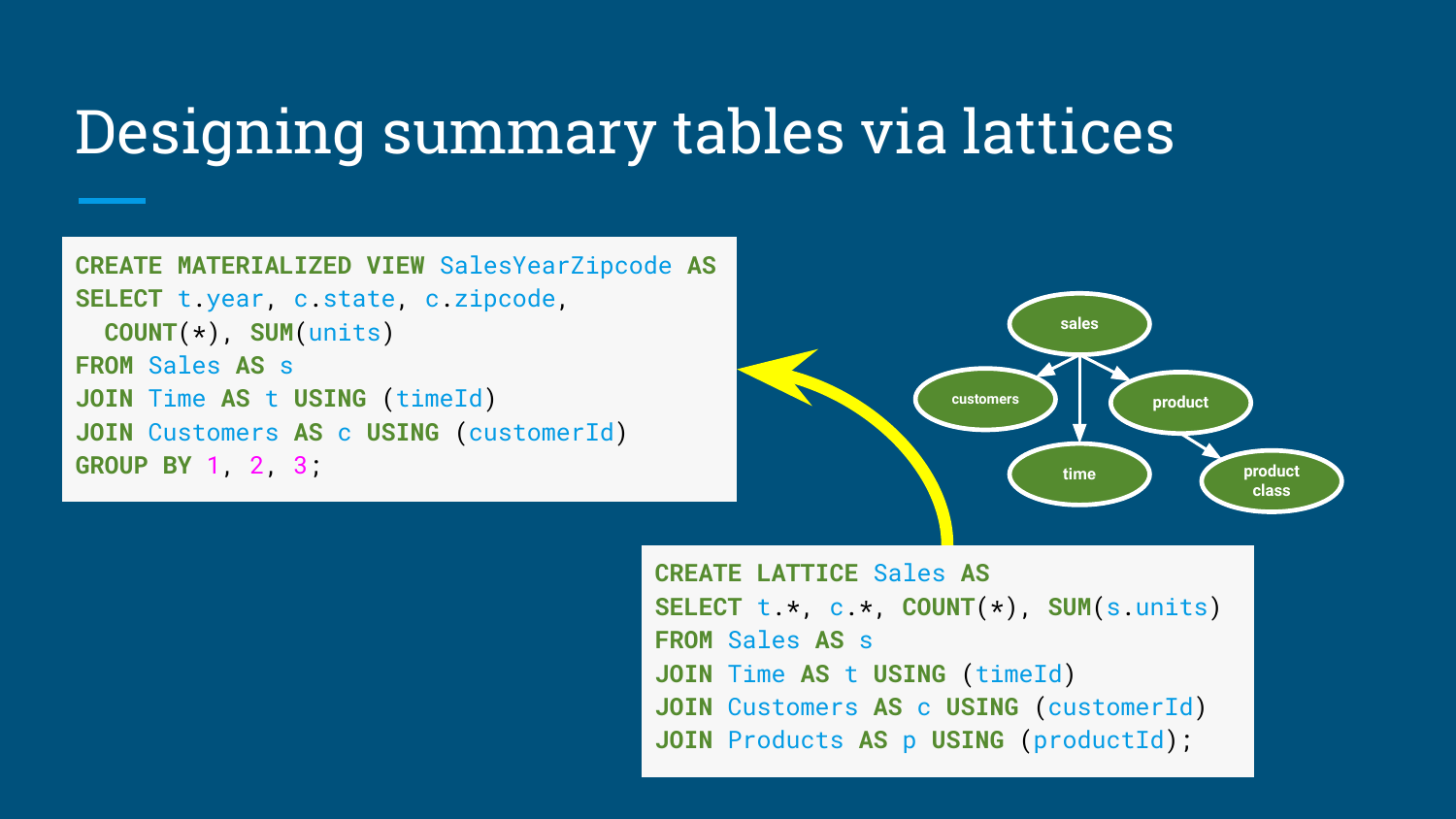
图:通过 Lattice 描述星型模型,并为常用维度组合设计汇总表
讲义中用五个维度说明组合空间:
z: zipcode,约 43k 个取值。s: state,约 50 个取值。g: gender,2 个取值。y: year,5 个取值。m: month,12 个取值。
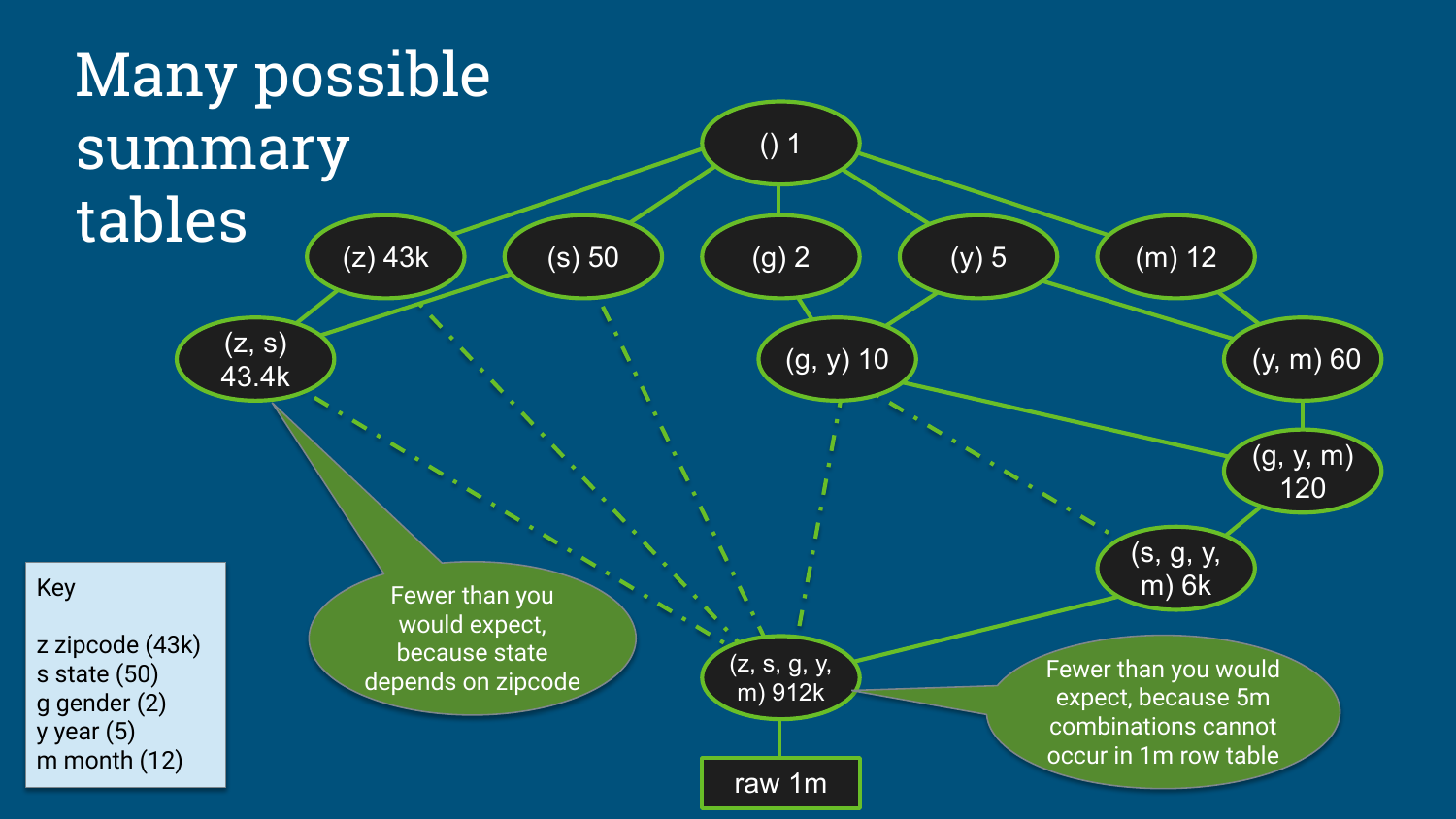
图:维度组合会形成大量候选汇总表,真实基数受数据规模和函数依赖约束
直觉上 (z, s, g, y, m) 的组合数会很大,但真实数据会受到两个约束:原始表只有 1m 行,实际出现的组合不会超过原始行数;state 依赖 zipcode,因此 (z, s) 的组合数接近 zipcode 数量,简单相乘会明显高估。这些基数和函数依赖会影响物化选择。
Hyde 在讲义里提到 AdaptiveMonteCarloAlgorithm。它基于 Harinarayan、Rajaraman、Ullman 1996 年关于数据立方体高效实现的研究,用贪心方式选择高收益汇总表:

图:AdaptiveMonteCarloAlgorithm 用成本收益模型选择汇总表
- 成本是候选汇总表的大小。
- 收益是它在模拟或历史查询负载上节省的查询时间。
- 目标是在存储预算内选出整体收益最高的一组汇总表。
这和前文的数据立方体问题接得上:前文解释“为什么不能全部物化”,这里说明“系统怎样选择一小部分物化”。
自适应数据系统:让推荐器参与数据组织
分享最后落在 Adaptive data systems。系统持续接收三类信号:
queries: 查询历史和访问模式。DML: 数据变化和更新频率。statistics: 基数、分布、函数依赖和成本估计。
这些信号进入推荐器,输出可执行的数据组织动作:
- 把磁盘块缓存到内存。
- 缓存查询结果。
- 按新的 key 重新分区。
- 创建二级结构,例如
b-tree或r-tree索引。 - 创建、刷新或淘汰物化视图。
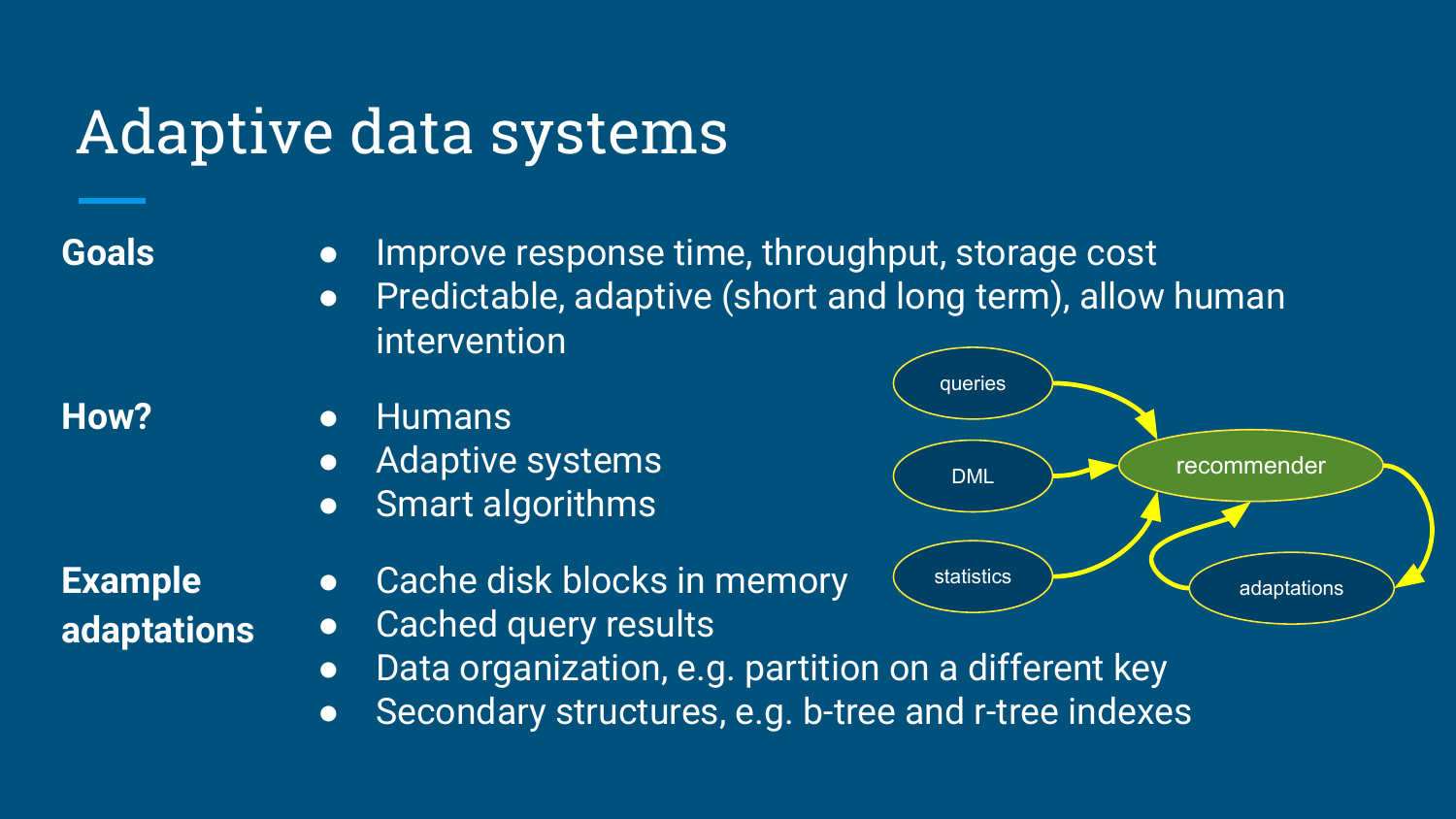
图:自适应数据系统通过查询、DML 和统计信息驱动数据组织调整
这里的目标包括响应时间、吞吐、存储成本和可预测性。生产系统里的自动化需要明确的人工边界:预算、关键物化表冻结、刷新窗口、推荐结果审计。自适应系统负责发现机会和执行低风险动作,数据工程师负责守住边界、治理和生产稳定性。
工程上的落点
把这场分享和前文合起来看,落到 Calcite 相关的数据优先工程,大概有五件事。
用关系代数表达派生关系。视图、索引、汇总表、缓存结果都应尽量保留来源表达式,让优化器能判断等价关系。
把统计信息纳入数据工程。没有基数、分布和函数依赖,Lattice 只能枚举候选项,无法可靠计算成本收益。
把 BI 语义层当作数据工程入口。LookML 这类模型变化能暴露真实业务访问路径,派生表可以先临时化,再持久化,再透明化。
为物化视图建立完整生命周期。设计、填充、维护、重写、适配和表达都要有人管。只做建表和刷新,会把后续维护压力留给人工 SQL。
给系统保留干预面。自动推荐可以处理日常优化,生产环境仍需要预算、权限、刷新策略和回滚机制。
这场 Tactical Data Engineering 最有意思的地方,是把 DBMS 里成熟的数据组织能力,放回现代数据流水线这个更分散的环境里看。前文讲原则:查询性能来自数据组织。本文顺着 Hyde 的分享往下看实现:Calcite 这类框架如何把数据组织放进代数表达、规则重写、代价选择和持续维护之中。
参考资料
- Tactical Data Engineering - AI Council
- Tactical Data Engineering - YouTube
- Tactical Data Engineering - Data Council
- Tactical Data Engineering Slides
- Apache Calcite
- Calcite Lattices
- Harinarayan, Rajaraman, Ullman. Implementing data cubes efficiently. SIGMOD 1996.
写在最后
笔者因为工作原因接触到 Calcite,前期学习过程中,深感 Calcite 学习资料之匮乏,因此创建了 Calcite 从入门到精通知识星球,希望能够将学习过程中的资料和经验沉淀下来,为更多想要学习 Calcite 的朋友提供一些帮助。

欢迎关注
欢迎关注「端小强的博客」微信公众号,会不定期分享日常学习和工作经验,欢迎大家关注交流。
