
JDBC API 为 Java 程序提供了一种访问一个或多个数据源的方式。在大多数情况下,数据源是关系型 DBMS,其数据通过 SQL 访问。不过,也可以在其他数据源之上实现支持 JDBC 技术的驱动程序,例如遗留文件系统或面向对象系统。JDBC API 的主要目标,是为应用程序提供一套访问多种数据源的标准 API。
本章介绍 JDBC API 的一些关键概念,并说明 JDBC 应用程序的两种常见部署模型。两层模型和三层模型都是逻辑上的划分方式,可以映射到不同的物理部署形态。
4.1 建立连接
JDBC API 定义了 Connection 接口,用于表示与底层数据源之间的连接。
在典型场景中,JDBC 应用程序会通过以下两种机制之一连接到目标数据源:
DriverManager:这是一个在最早的JDBC 1.0 API中就已引入的完整实现类。当应用程序首次尝试通过指定URL连接数据源时,DriverManager会自动加载在CLASSPATH中找到的JDBC驱动程序。对于JDBC 4.0之前的驱动程序,通常需要由应用程序显式加载。DataSource:该接口在JDBC 2.0 Optional Package API中引入。相比DriverManager,它更适合生产环境,因为它能够把底层数据源的配置细节隐藏在对象属性之后。应用程序只需调用其getConnection方法,即可获得到特定数据源的连接。只要修改DataSource对象的属性,应用程序就可以被重定向到不同的数据源,而无需修改业务代码。
JDBC API 还定义了 DataSource 的两个重要扩展,以支持企业应用程序场景:
ConnectionPoolDataSource:支持物理连接的缓存与重用,从而提升性能和可扩展性。XADataSource:提供能够参与分布式事务的连接。
4.2 执行 SQL 语句与操作结果
建立连接后,应用程序便可以借助 JDBC API 对目标数据源执行查询和更新。JDBC API 提供了对 SQL:2003 中常见能力的访问。由于不同供应商对这些能力的支持程度不完全一致,JDBC API 提供了 DatabaseMetaData 接口,使应用程序能够在运行时判断当前数据源是否支持某项特性。
此外,JDBC API 还定义了转义语法,以便应用程序访问非标准的供应商特定能力。转义语法的价值在于,它允许 JDBC 应用程序在保持可移植性的同时,尽量获得与本地应用程序接近的功能覆盖。
应用程序通过 Connection 接口中的方法来设置事务属性,并创建 Statement、PreparedStatement 或 CallableStatement 对象。这些语句对象用于执行 SQL 语句并检索结果。ResultSet 接口则封装了查询返回的结果。语句还可以批量执行,从而允许应用程序将多个更新请求作为一个执行单元提交给数据源。
JDBC API 还通过 RowSet 接口扩展了 ResultSet,从而为表格数据提供了比标准结果集更通用的容器。RowSet 对象是一个 JavaBeans 组件,可以在断开与数据源连接后继续工作。例如,RowSet 实现可以被序列化并通过网络传输,这对不希望持有持续连接的小型客户端尤其有用。RowSet 还可以通过自定义读取器访问多种表格数据格式,而不仅仅是关系数据库中的数据;它也可以在离线状态下修改数据,并通过自定义写入器将更新写回底层数据源。
4.2.1 支持 SQL 高级数据类型
JDBC API 定义了标准映射,用于在 SQL 数据类型与 JDBC 数据类型之间进行转换。这包括对 SQL:2003 高级数据类型的支持,例如 BLOB、CLOB、ARRAY、REF、STRUCT、XML 和 DISTINCT。JDBC 驱动程序还可以为用户定义类型(UDT)实现一个或多个自定义类型映射,使 UDT 能够映射为 Java 编程语言中的类。JDBC API 还支持外部管理的数据,例如存放在数据源之外文件中的数据。
4.3 两层模型
两层模型将功能划分为客户端层和服务器层,如图 4-1 所示。
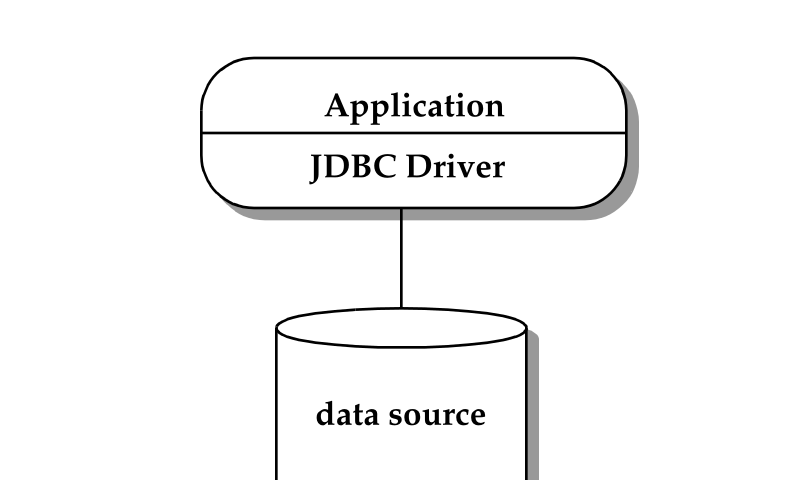
图 4-1 两层模型
客户端层包括应用程序以及一个或多个 JDBC 驱动程序。此时,应用程序需要承担以下职责:
- 表示逻辑
- 业务逻辑
- 多语句事务或分布式事务的事务管理
- 资源管理
在该模型中,应用程序会直接与 JDBC 驱动程序交互,包括建立和管理物理连接,以及处理底层数据源实现的细节。应用程序也可以利用自己对特定实现的了解,使用非标准特性或进行性能调优。
这种模型的一些缺点包括:
- 将表示逻辑与业务逻辑和基础设施逻辑混杂在一起,不利于形成清晰、可维护的系统架构。
- 由于应用程序往往针对特定数据库实现进行调优,可移植性较差。若应用程序需要连接多个数据库,还必须了解不同厂商实现之间的差异。
- 可扩展性受限。应用程序通常会在整个生命周期中持有一个或多个物理数据库连接,从而限制系统可支持的并发规模。
4.4 三层模型
三层模型引入了中间层服务器来承载业务逻辑和基础设施,如图 4-2 所示。
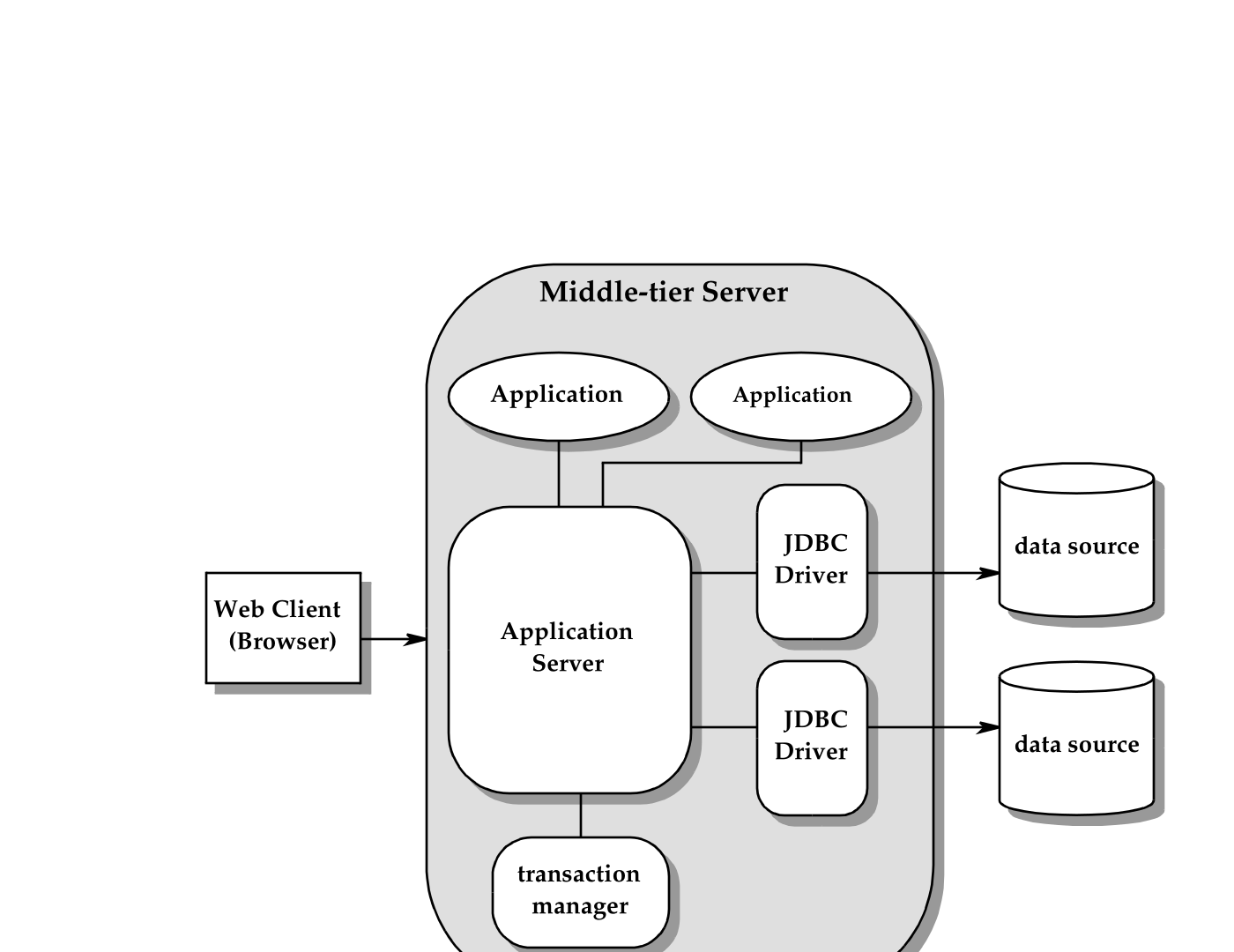
图 4-2 三层模型
这种架构旨在为企业应用程序提供更好的性能、可扩展性和可用性。其功能划分如下:
- 客户端层:实现面向人机交互的表示逻辑。典型实现包括
Java程序、Web浏览器和PDA。客户端只与中间层应用程序交互,不需要了解底层数据源和基础设施的实现细节。 - 中间层服务器:承担两部分职责。
- 一部分是与客户端交互并实现业务逻辑的应用程序。如果应用程序需要访问数据源,它通常面对的是更高层的抽象,例如
DataSource对象和逻辑连接,而不是更底层的驱动程序API。 - 另一部分是为应用程序提供基础设施支持的应用服务器。这可能包括物理连接的管理与池化、事务管理,以及对不同
JDBC驱动程序差异的屏蔽。应用服务器角色通常可以由Java EE服务器承担。
- 一部分是与客户端交互并实现业务逻辑的应用程序。如果应用程序需要访问数据源,它通常面对的是更高层的抽象,例如
- 底层数据源:即数据存放的地方。它可以是关系型
DBMS、遗留文件系统、面向对象DBMS、数据仓库、电子表格或其他能够打包与提供数据的系统。唯一的前提是存在相应的、支持JDBC API的驱动程序。
4.5 Java EE 平台中的 JDBC
Java EE 组件,例如 JavaServer Pages、Servlets 和 Enterprise JavaBeans(EJB)组件,通常需要访问关系数据,并通过 JDBC API 完成此类访问。当 Java EE 组件使用 JDBC API 时,容器会负责管理事务与数据源。这意味着组件开发者通常不需要直接处理 JDBC API 中与事务管理和数据源管理相关的底层能力。更多信息可参阅 Java EE 平台规范。